Using DaCy#
To use the model you first have to download either the small, medium or large model. To see a list of all available models:
import dacy
for model in dacy.models():
print(model)
# da_dacy_small_tft-0.0.0
# da_dacy_medium_tft-0.0.0
# da_dacy_large_tft-0.0.0
Note
The name of the indicated language (da), framework (dacy), model size (e.g.
small), model type (tft),and model version (0.0.0)
From here we can now download a model using:
nlp = dacy.load("da_dacy_medium_tft-0.0.0")
# or equivalently
nlp = dacy.load("medium")
Which will download the model to the .dacy directory in your home directory.
If the model is already downloaded the model will be loaded. To download
the model to a specific directory:
# Just download
dacy.download_model("da_dacy_medium_tft-0.0.0", your_save_path)
# Download and load
nlp = dacy.load("da_dacy_medium_tft-0.0.0", your_save_path)
Using this we can now apply DaCy to text with conventional SpaCy syntax:
doc = nlp("DaCy er en hurtig og effektiv pipeline til dansk sprogprocessering bygget i SpaCy.")
See also
DaCy is built using SpaCy, hence you will be able to find a lot of the required documentation for using the pipeline in their very well written documentation on their website
Tagging named entities#
A named entity is a “real-world object” that’s assigned a name – for example, a person, a country, a product or a book title. DaCy can recognize organizations, persons, and location, as well as other miscellaneous entities.
for entity in doc.ents:
print(entity, ":", entity.label_)
# DaCy : ORG
# dansk : MISC
# SpaCy : ORG
We can also plot these using:
from spacy import displacy
displacy.render(doc, style="ent")
See also
For more on named entity recognition see SpaCy’s documentation.

Tagging parts-of-speech#
print("Token POS-tag")
for token in doc:
print(f"{token}: {token.pos_}")
# Token POS-tag
# DaCy: PROPN
# er: AUX
# en: DET
# hurtig: ADJ
# og: CCONJ
# effektiv: ADJ
# pipeline: NOUN
# til: ADP
# dansk: ADJ
# sprogprocessering: NOUN
# bygget: VERB
# i: ADP
# SpaCy: PROPN
# .: PUNCT
See also
For more on Part-of-speech tagging see SpaCy’s documentation.
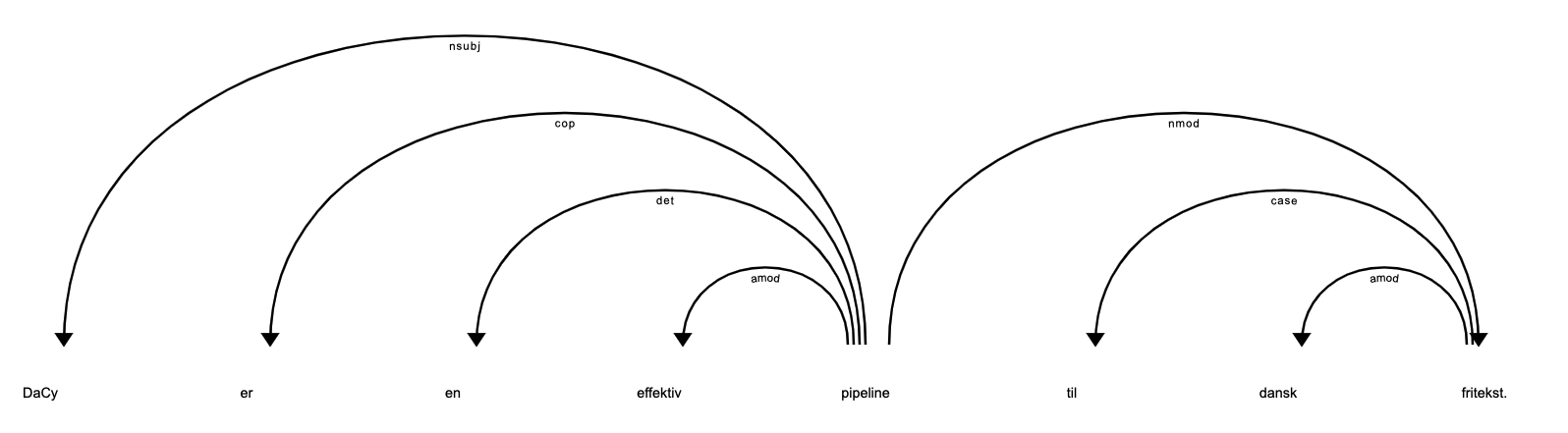
Dependency parsing#
DaCy features a fast and accurate syntactic dependency parser. In DaCy this dependency parsing is also used for sentence segmentation and detecting noun chunks.
You can see the dependency tree using:
doc = nlp("DaCy er en effektiv pipeline til dansk fritekst.")
from spacy import displacy
displacy.render(doc)
See also
For more on dependency parsing with DaCy, especially on how to navigate the tree, see SpaCy’s documentation.
More guides and tutorials#
DaCy also includes a couple of additional tutorials which are available as a notebook on Google’s Colab.
Google Colab |
Content |
|---|---|
|
A simple introduction to the new sentiment features in DaCy. |
|
A guide on how to augment text using the DaCy augmenters. |
|
A guide on how to use augmenters to measure model robustness and biases. |
|
A guide on how to wrap an already fine-tuned transformer and add it to your SpaCy pipeline using DaCy helper functions. |